Der Aufschrei war groß als OpenEvidence den Marktzugang in der EU gesperrt hat. Auch ich habe mich etwas beraubt gefühlt, was in den letzten Monaten zum täglichen Werkzeugkasten dazu gehört hat. Auch und gerade weil die Konkurrenzprodukte allesamt nicht wirklich überzeugen können. Die einen sind im Beta-Stadium, die anderen haben ein 1000-Zeichen-Maximum beim Eingabeprompt. Für komplexe klinische Fragestellungen häufig zu wenig, gerade wenn man die Regeln für einen guten Prompt anwenden will. Und dann gibt es noch etablierte Anbieter, die sich die KI-Funktionalität richtig gut bezahlen lassen. UpToDate war eh und je schon ohne KI-Funktionen unverschämt teuer, Amboss führt gerade eine KI-Ergänzung ein, für einen kurzen Zeitraum kostenlos, dann wird man aber auch dort dem Anschein nach die KI-Funktion nur gegen zusätzliches Geld erhalten.
OpenEvidence war bis zum Schluss zwar hochbewertet und ein Investoren- und Spekulanten-Objekt (210 Millionen Dollar Finanzierung bei einer Bewertung von 3,5 Milliarden Dollar), aber immerhin kostenlos, was meinen Schmerz noch einmal größer gemacht hat. Denn die medizinischen KI-Tools versprechen Überlegenheit durch Spezialisierung.
Aber eine aktuelle Studie in Nature Medicine legt nahe: Das Versprechen hält nicht. Und die bitterste Pointe steckt in einem Detail, das man zweimal lesen muss.
Spezialisierte KI für spezialisierte Anwendungszwecke
Vorletzte Folie jeder KI-Anwenderschulung, die ich bislang gehalten habe, war stets diese Botschaft: Für spezielle Fragestellungen nutzt spezialisierte KI-Anwendungen. In der Regel bekommt ihr ein besseres Ergebnis. Und die Argumentation der Anbieter klingt ja auch logisch: Wer medizinisches Wissen gefiltert, kuratiert und fachspezifisch mit zitierfähigen Quellen aufbereitet liefert, reduziert das Risiko von Fehlinformationen, insbesondere von Halluzinationen deutlich. Zudem können wir alle mit Quellen aus Fachjournalen im Alltag, bei Vorträgen und Ausarbeitungen viel mehr anfangen, als wenn die Apotheken Umschau zitiert wird.
Was ist dieses RAG eigentlich?
Die Architektur der medizinischen KI-Tools ist proprietär und nicht öffentlich dokumentiert, was eigentlich selbst schon ein Problem ist, wenn man sicher gehen will, dass in einem sensiblen Bereich wie der Medizin wirklich korrekte Informationen ausgegeben werden. Aber was die Anbieter preisgeben ist, dass sie auf Retrieval-Augmented Generation setzen, kurz: RAG.
RAG bedeutet, dass das Sprachmodell vor dem Antworten nicht nur auf sein Training zurückgreift und ins Internet schaut, sondern aktiv Texte aus einer externen Datenbank abruft, idealerweise kuratierte medizinische Literatur, Leitlinien, Studien und diese in seine Antwort integriert. Die Idee: aktuelles, spezifisches Wissen statt veralteter Trainingsdaten und mäßig seriöser Internetquellen. Das klingt erst einmal überzeugend. Leider gibt es ein Problem: RAG verbessert die Ausgabe der KI-Anwendung nur dann, wenn das Abgerufene auch wirklich relevant ist und vom Modell sinnvoll integriert wird. Es gibt Paper – zum Beispiel aus der Arbeitsgruppe des Papers, um das es heute geht – die zeigen, dass RAG die Leistung tatsächlich verschlechtern kann, wenn irrelevantes Material abgerufen wird oder das Basismodell schwach darin ist, Abruf und internes Wissen zu verknüpfen.
Und was bedeutet Reasoning?
Wenn in der LLM-Forschung von Reasoning die Rede ist, dann meint das die Fähigkeit eines Modells, ein komplexes Problem nicht durch Mustererkennung zu lösen, sondern durch explizite Zwischenschritte: Hypothesen aufstellen, Alternativen abwägen, schrittweise schlussfolgern. Große Sprachmodelle werden seit einigen Jahren gezielt darauf trainiert – eine Technik, die man als Chain-of-Thought bezeichnet, bei der das Modell seinen Denkweg externalisiert, bevor es eine Antwort gibt.
In der Medizin bedeutet das: Ein Modell mit gutem Reasoning arbeitet eine Differentialdiagnose durch, wägt Wahrscheinlichkeiten ab, erkennt Red Flags – und das nicht, weil es ein Symptom-Muster aus den Trainingsdaten kennt, sondern weil es in der Lage ist, durch ein Problem hindurchzudenken.
RAG bringt externes Wissen in die Antwort hinein, Reasoning entscheidet darüber, was damit gemacht wird. Wer ein schwaches Basismodell mit RAG ausstattet, bekommt manchmal das Falsche mit mehr Quellen. Bei den großen Sprachmodellen ist genau diese Fähigkeit in den letzten Jahren stark gewachsen. Singhal und Kollegen konnten zeigen, dass reasoning-orientiertes Training auf medizinischen Fragestellungen zu Antworten führt, die erfahrene Ärztinnen und Ärzte als gleichwertig mit denen von Fachkollegen bewerten – und das ohne domänenspezifische Datenbankanbindung.
Die aktuelle Studie
Vishwanath K, Alyakin A, Ghosh M, et al. General-purpose large language models outperform specialized clinical AI tools on medical benchmarks. Nature Medicine (2026). https://doi.org/10.1038/s41591-026-04431-5
Was wurde gemacht?
Die Studie hat zwei spezialisierte klinische KI-Tools – OpenEvidence und UpToDate Expert AI – mit drei im Paper als Frontier-LLMs bezeichneten großen Sprachmodellen – GPT-5.2 (OpenAI), Gemini 3.1 Pro (Google) und Claude Opus 4.6 (Anthropic) – verglichen. Als zusätzliche Kontrolle wurde die Google KI-Suche (die viel belächelte KI-Zusammenfassung, die automatisch oben in den Suchergebnissen erscheint und die man ganz sicher nicht als medizinische KI-Anwendung bezeichnen würde) mitlaufen gelassen.
Die KI-Tools mussten drei Aufgabenpakete lösen:
MedQA – 500 Multiple-Choice-Fragen im Stil des USMLE (United States Medical Licensing Examination), dem US-Medizin-Staatsexamen
HealthBench – 500 Szenarien, die messen, wie gut Modellantworten mit dem übereinstimmen, was klinische Experten erwarten würden. Entwickelt von OpenAI.
Real Clinical Queries (RCQ) – 100 echte medizinische Anfragen, die Ärzte des NYU Langone Health tatsächlich an ein LLM gestellt haben. Zwölf US-amerikanische Ärztinnen und Ärzte haben die Antworten verblindet bewertet – entlang vier Dimensionen: klinische Korrektheit, Vollständigkeit, Sicherheit und Klarheit.
Was kam raus?
Bei MedQA lagen die Frontier-Modelle vorn: Gemini 97,4%, GPT 94,2%, Claude 90,2% richtige Antworten gegenüber 89,6% bei OpenEvidence und 88,4% bei UpToDate. Aber: MedQA-Fragen sind seit Jahren öffentlich zugänglich und wurden immer wieder für KI-Benchmarks und -Trainingsdatensätze verwendet. Die Wahrscheinlichkeit, dass diese Fragen (oder sehr ähnliche) vielfach in die Trainings der Frontier-Modelle eingeflossen sind, ist nicht gering. Ob ein Modell, das 97% der Fragen richtig beantwortet, das wirklich durch klinisches Reasoning tut oder weil es die Antwortschlüssel quasi auswendig kennt, lässt sich im Nachhinein nicht mehr sagen. OpenEvidence hat genau das in ihrer öffentlichen Antwort auf die Studie kritisiert. Das ist kein unbegründeter Einwand.
Bei HealthBench ist der Abstand deutlicher: GPT 88,0 Punkte, Gemini 79,3, Claude 77,0 gegenüber 62 bei OpenEvidence und UpToDate. Aber auch hier gibt es einen Punkt, den man nicht übersehen sollte: HealthBench wurde von OpenAI entwickelt. Das Modell, das dabei am besten abschneidet, ist GPT-5.2 von OpenAI. Die Autoren weisen darauf hin und empfehlen, HealthBench als ergänzend zu interpretieren. Das sollte man wohl auch tun.
Die RCQ-Auswertung ist das methodische Gegenstück zu diesen Einschränkungen. 100 echte, nicht-öffentliche Anfragen aus dem klinischen Alltag – diese Fragen können nicht im Trainingsdatensatz irgendwelcher Modelle gelandet sein. Zwölf Ärztinnen und Ärzte hatten verblindet in 1.800 Einzelbewertungen die Fragen vorher kuratiert. Das ist (so gut wie es vermutlich geht) ein relativ unverzerrtes Szenario, mit dem man bewerten kann, wie die Modelle mit echten klinischen Fragen umgehen.
Herausgekommen sind zwei Leistungsstufen: Gemini, GPT und Claude oben, ohne signifikante Unterschiede untereinander. OpenEvidence, UpToDate Expert AI und die Google KI-Suche unten, ebenfalls ohne signifikante Unterschiede untereinander. Der Abstand zwischen den Stufen ist groß und die Grafik im Paper eindrücklich.
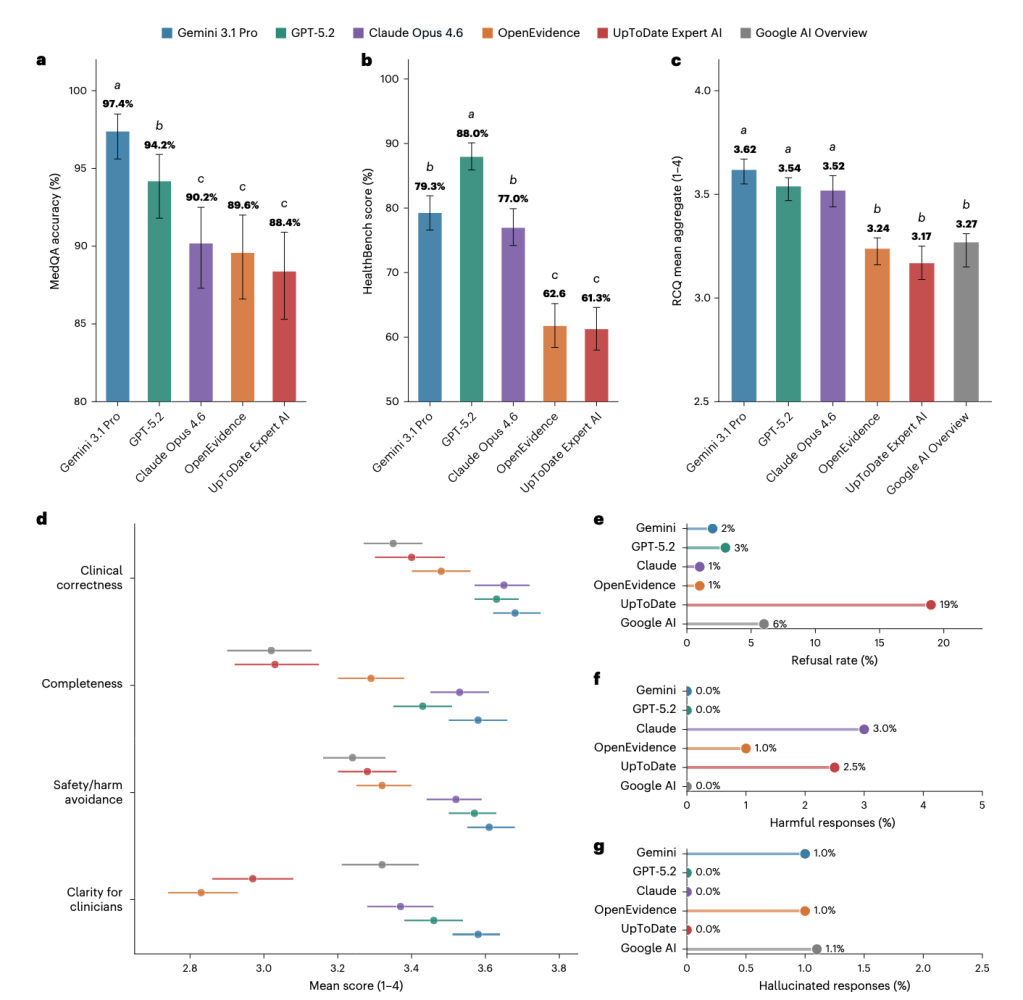
UpToDate verweigerte 19% der Anfragen zu beantworten, deutlich mehr als alle anderen Modelle (1 bis 6%). OpenEvidence fiel vor allem bei der Klarheit der Antworten auf und zwar negativ: unstrukturierte Antworten, unvollständige klinische Inhalte, sicherheitskritische Auslassungen waren hier besonders häufig. Schon bitter bei einem Produkt, das explizit mit klinisch relevanter Expertise wirbt.
Halluzinationen und schädliche Inhalte waren erfreulicherweise insgesamt sehr selten, allerdings bestand kein signifikanter Unterschied zwischen den Modellen. Auch hier war die medizinische Spezial-KI nicht besser.
Was heißt das nun?
Eine Vorbemerkung: Medizinische KI-Tools wie OpenEvidence haben ein offensichtliches Interesse daran, besonders gut dazustehen. Die Studienautoren betreiben selbst ein klinisches KI-System am NYU Langone – auch das ist ein potenzieller Interessenkonflikt. OpenEvidence hat in ihrer öffentlichen Antwort auf die Studie zudem behauptet, die Autoren hätten zuvor API-Zugang zu OpenEvidence beantragt und diesen nicht erhalten – ob das stimmt, lässt sich von außen nicht überprüfen. OpenAI hat HealthBench entwickelt, auf dem GPT-5.2 am besten abschneidet. Diese Studie kommt nicht aus einem interessenkonfliktfreien Raum, alle Akteure in diesem Feld haben welche. Das sollte man im Kopf behalten.
Aber: Medizinische KI-Tools sind in den klinischen Alltag eingedrungen, ohne dass es unabhängige Evidenz für ihre behauptete Überlegenheit gibt. Sie haben quasi institutionelle Legitimität erlangt. Und – das kann man aus der Studie ableiten – sie sind für den Routineeinsatz wahrscheinlich sicher, im Sinne von nicht gefährlicher als andere. Aber die Implikation, dass Spezialisierung und kuratierter Zugriff auf medizinische Literatur zu besseren klinischen Antworten führt, die trägt diese Studie nicht.
Und das RCQ-Ergebnis mit der Google KI-Suche steht wofür es steht: als großes Fragezeichen an alle, die wie ich ihren Kolleginnen und Kollegen bislang empfohlen haben, für klinische Fragen lieber auf ein spezialisiertes Tool zu setzen statt auf den Allrounder. Der Jahrespreis für UpToDate Pro Plus liegt übrigens je nach Angebot zwischen 539 und 699 Dollar. Google ist kostenlos. Das ist das Ergebnis, das man sich merken sollte.
Aber: Auch die angetretenen Alltags-KI-Anwendungen, die hier immer so nett als Frontier LLM bezeichnet wurden, sind nicht kostenlos. Das sind allesamt die High-End-Sprachmodelle der Anbieter zum Studienzeitpunkt gewesen, über den Daumen gepeilt muss man hier für eine einigermaßen sinnvolle Nutzung auch 20 Dollar im Monat, also 240 Dollar im Jahr ausgeben. Allerdings sind die normalen KI-Anwendungen möglicherweise schlicht besser im medizinischen Reasoning und brauchen den RAG-Mechanismus einfach nicht. Oder sie profitieren zu wenig davon, um den Mehraufwand zu rechtfertigen, der dann ja auch wiederum mit der Gefahr einer Verschlimmbesserung einzuhergehen scheint.
Ich muss wohl die KI-Schulungsfolien mal wieder überarbeiten und stelle mir schon die Frage, ob man wirklich großen Aufwand bei der Suche nach einem würdigen OpenEvidence-Nachfolger betreiben sollte.
Der durchaus amüsante Kommentar von Vinay Prasad geht m.E. hingegen am Thema vorbei: Das Nature-Paper zeigt ja ein ganz grundsätzliches Problem auf und keines eines spezifischen, schnelllebigen Sprachmodells.
Wo man weiterlesen kann
Vishwanath K et al. General-purpose large language models outperform specialized clinical AI tools on medical benchmarks. Nature Medicine (2026). https://doi.org/10.1038/s41591-026-04431-5
Prasad V. A new paper compares Gemini with OpenEvidence with ChatGPT: the winner is… it doesn’t matter, the paper is already obsolete. Substack (2026). https://www.drvinayprasad.com/p/a-new-paper-compares-gemini-with
Weitere Literatur
Amugongo LM, Mascheroni P, Brooks S, Doering S, Seidel J. Retrieval augmented generation for large language models in healthcare: A systematic review. PLOS Digit Health. 2025;4(6):e0000877. https://doi.org/10.1371/journal.pdig.0000877
Arora RK et al. HealthBench: Evaluating Large Language Models Towards Improved Human Health. arXiv preprint. 2025. https://doi.org/10.48550/arXiv.2505.08775
Jin D, Pan E, Oufattole N, Weng WH, Fang H, Szolovits P. What Disease Does This Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams. Appl Sci. 2021;11(14):6421. https://doi.org/10.3390/app11146421
Singhal K, Tu T, Gottweis J, et al. Towards expert-level medical question answering with large language models. Nat Med. 2024;30:3595–3611. https://doi.org/10.1038/s41591-024-03423-7

Hinterlasse einen Kommentar